
LLMs need their heads read!
A 'Best Paper' at NeurIPS makes LLMs faster & more stable by adding a gate on each attention head. This turned attention from a free‑for‑all into a clean arbitration engine. But why does this work?


Open an attention visualiser (for example BertViz) on a large language model and you may notice an odd pattern.
You feed it a long prompt – a system message, some instructions, a few examples, a user query, maybe some retrieved context. Tokens everywhere. And then you look at the attention patterns and much of the mass is drawn to the first token (often something like [CLS] that you see at the start of one edge of the BertViz plots - see below).
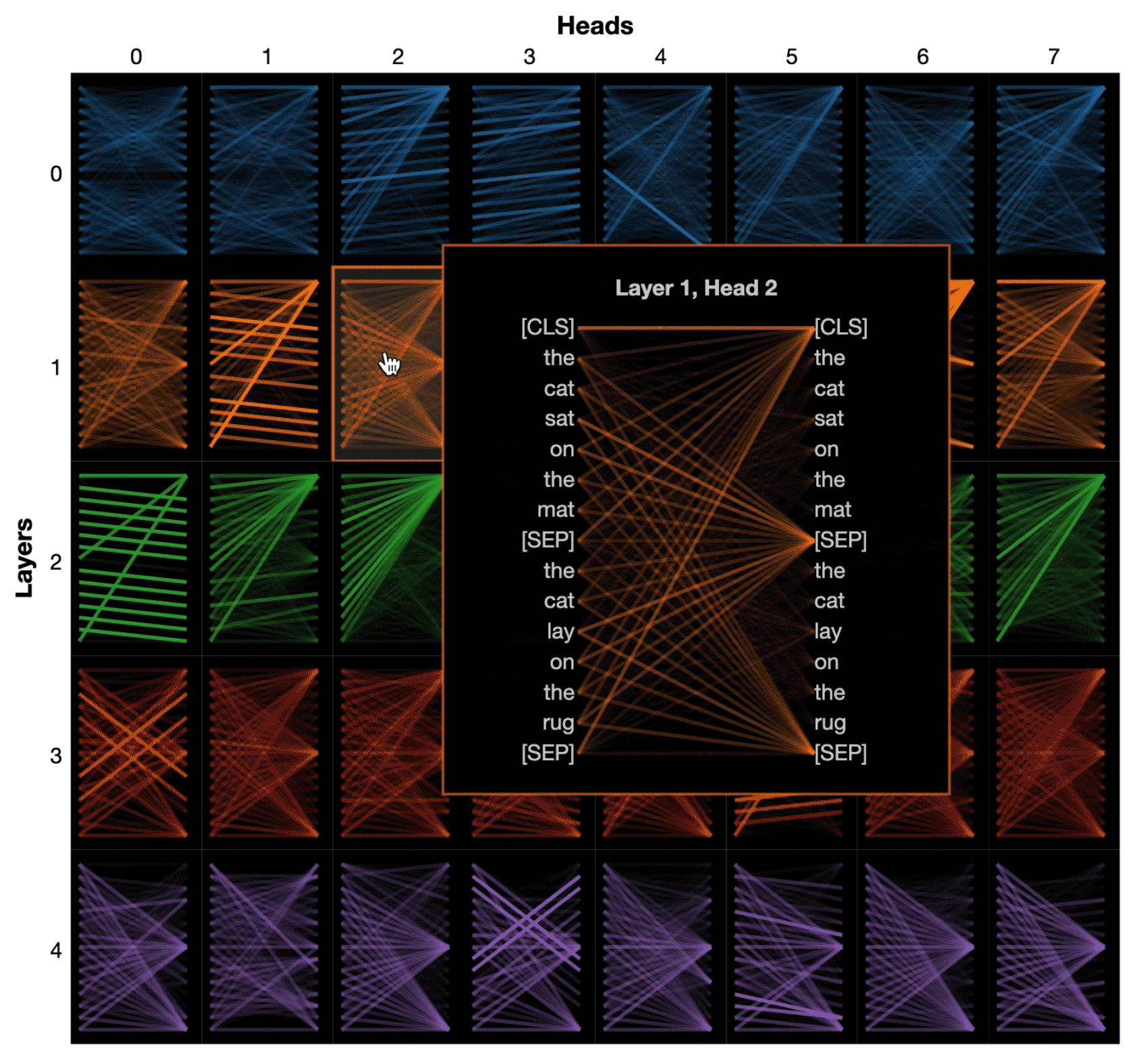
It doesn’t matter whether that first token is a system prompt, a role marker, or just the model’s special “start of sequence” [CLS] token. Across many layers and heads there’s a recurring pattern of attention snapping back to the start of the sequence.
From the outside, this shows up as a very particular kind of brittleness. Tiny changes early in the prompt can flip the whole answer. Long context gets ignored in favour of whatever was said at the top. Attempts to add nuance or correction late in the prompt mysteriously don’t stick.
We call these attention-sinks and they are mostly treated as “just a quirk” of how transformers work.
At NeurIPS this year, the gated‑attention paper won a ‘Best Paper’ award for almost completely eliminating this behaviour, using a tiny architectural change - a small, head‑specific gate applied after attention.
If you look at this one way, it’s a clever and simple hack.
But look at it through the lens of arbitration (how models decide which of their internal processes gets to move the state next) and it looks more like this:
We gave the model a way to decide, token by token, which heads are allowed to speak.
And once you see it that way, a much richer story opens up.
The default story about the gate
Here’s the “Gated Attention for Large Language Models” paper in a simple pass.
In a standard transformer layer, each attention head computes a weighted sum over values. Those per‑head outputs are concatenated and passed through a linear projection back into the residual stream.
The authors insert one simple thing - after each head’s attention output has been computed and before those outputs are mixed together by the final dense layer, they apply a small, head-specific and query-dependent sigmoid gate.

Conceptually, each head proposes an update for the current token. A tiny network (just a single linear layer with one output per head plus a sigmoid) looks at that token’s current hidden state and produces a number between zero and one. The head’s output is multiplied by that number before being added back to the stream.
Concretely, they take the current token’s hidden state x (the residual-stream vector coming into that attention block after layer norm), run it through that linear-plus-sigmoid layer to get one scalar per head, and use that scalar as a gate on each head’s SDPA (Scaled Dot Product Attention) output for that token.
Empirically, most of these numbers are very close to zero most of the time, so only a sparse subset of heads “get through” on any given token.
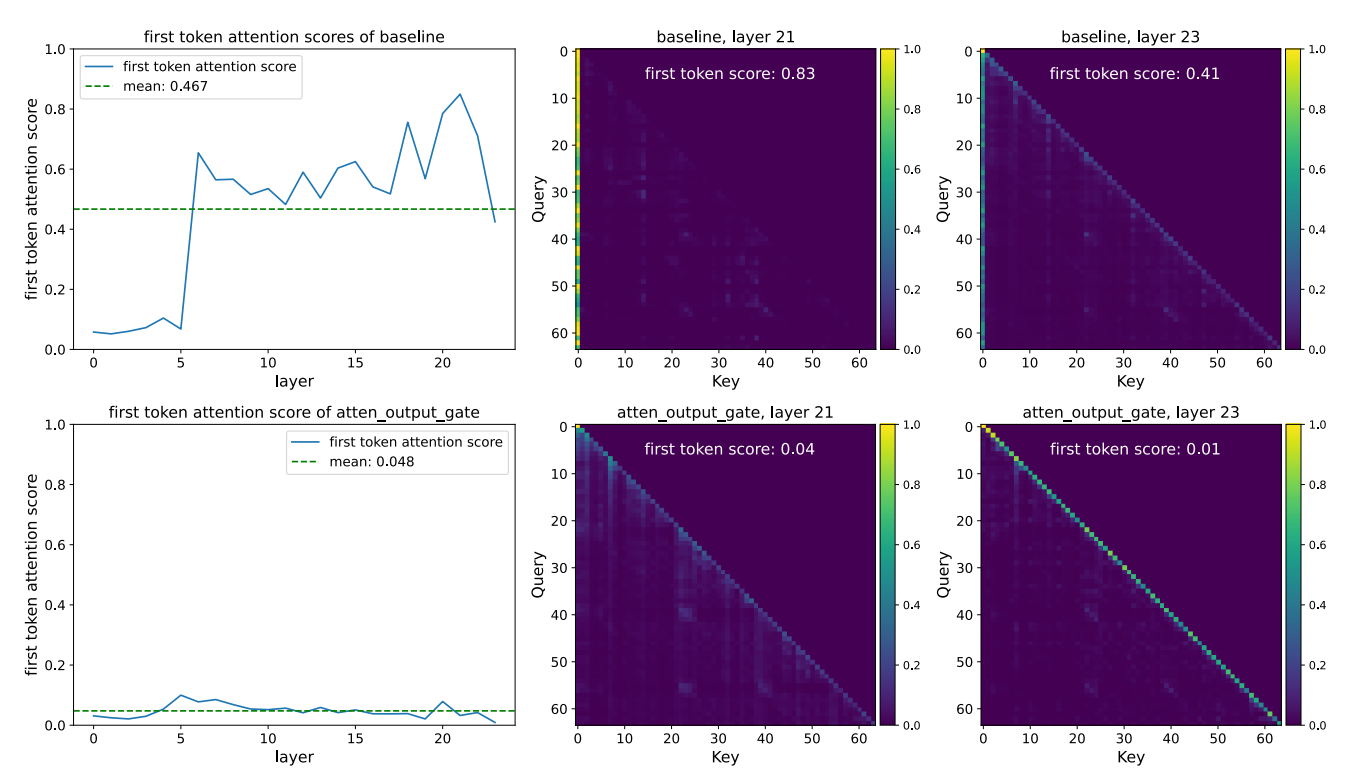
The headline benefits are exactly what you’d expect from a neat architectural tweak like this. Perplexity and benchmark scores improve at fixed parameter counts. Training becomes more stable, especially with larger learning rates and batch sizes. And attention-sinks mostly disappear. The first token stops attracting so much of the attention mass.
If you stay at that level, this seems like a neat optimisation trick. We added some non‑linearity and sparsity around attention. Gradients behave better. The model wastes less compute on useless heads. Sinks are an artefact we’ve regularised away. Job done!
All of that is true. It’s just not the whole story.
To see the deeper move, we need to review the 3‑process lens.
How an LLM continues a thought
On each token, a large model has (at least) three overlapping ways to decide what comes next.
First, it can lean on amortised state. The current hidden state acts as a compact representation of “where we are” in a concept, pattern, or task, and the model can read from that directly.
Second, it can engage in on‑the‑fly recompute. Instead of trusting a cached sense of the situation, it reaches back into the prompt for explicit support - definitions, constraints, examples, retrieved documents, earlier steps of reasoning, then recomputes what should happen now.
Third, it can fall back on anchors and scaffolds. Some tokens become structural anchors during training - system prompts, role markers, format examples, tool markers, or even arbitrary sink tokens. The model can simply keep aligning to whatever those anchors suggest.
In a clean world, these three processes cooperate. Amortised state gives you a compact sense of what’s going on. Recompute routes let you adapt, check, and reason. Anchors keep you on task and in style.
Sometimes the latent state says “we’re in a normal Q&A about aviation”, the recompute process says “we’re actually reasoning about a failure case in the checklist”, and the anchors say “the system prompt really wants upbeat marketing copy”.
Something has to decide which of those tendencies wins the next move in residual space.
That “something” (distributed across heads and layers) is what I call arbitration.
The 3‑process claim, in one line, is that a lot of what we call understanding or failure in LLMs comes down to which process (state, routes or anchors) wins the internal argument on each step.
Now let’s look back at the gate.
What the gate really does - deciding who gets to speak
The gated-attention paper’s authors claim non-linearity matters and argue that the value projection and output projection are linear, so adding the gate introduces necessary non-linearity to the low-rank mapping. They see this non-linearity as increasing expressiveness. I see it as a decision boundary.
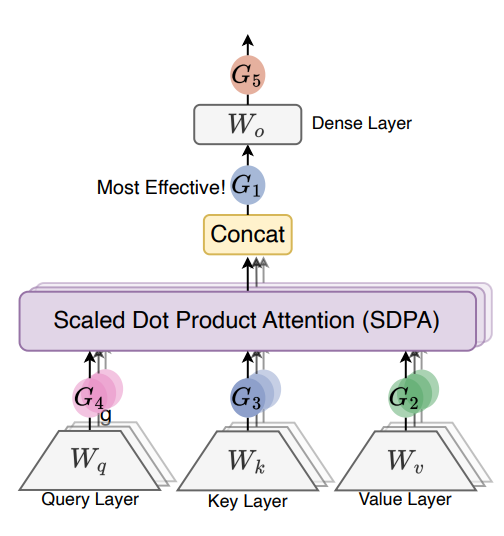
Mechanistically, the gated-attention paper adds a tiny network that looks at the current token’s hidden state and outputs a gate for each head. Viewed through the 3‑process lens, that’s not just extra non‑linearity. It’s a local, learned policy about which heads (and therefore which processes) should be allowed to move the model right now.
The researchers actually handed us a smoking gun for this theory. They tested two versions of the gate. The first looked at the “Value” (the content being retrieved from the past). The second looked at the “Query” (what the model is thinking about right now).
The Query version won by a landslide.
This is strong evidence that the decision to speak isn’t based on how “loud” or confident the memory is (the Value). It is based entirely on whether the model’s current state decides that memory is relevant. It is the present passing judgment on the past - exactly what you’d want if the model is choosing between routes, latents, and anchors..
Further, three aspects matter at once. The gate is per‑head, not shared, so different heads can be treated differently. That’s important because different heads play different roles - some behave like latent readers, some like route builders, some like anchor enforcers. The gate is also query‑dependent - it depends on the current token’s state, so its decisions change with task, content, stance, and phase of the conversation. And finally, the gate is strongly sparse - most values are near zero for most tokens, so only a few heads actually “get to speak” at each step.
Put that together and the story becomes simple. Each head proposes an update. The current state votes on whether that head is relevant. Only a small subset of heads win the right to move the residual stream and shape the geometry.
This is arbitration in miniature - they just haven’t called it that.
The most striking example of this is what happens to attention-sinks.
Attention-sinks as a failed arbitration regime
Why do attention-sinks happen at all?
Part of it is geometry. Attention weights are non‑negative and normalised, and the residual stream geometry means early tokens accumulate influence across layers. Over training, this gives those early tokens a structural advantage.
Certain heads learn an easy, general‑purpose behaviour - when in doubt, look back at the first token. Those heads end up behaving like crude anchor enforcers. They drag the model back to whatever lives at the start of the sequence, whether that’s a system prompt, a role instruction, a format example, or just an arbitrary symbol that happened to be there.
In the 3‑process view, this is a very specific failure mode. The anchor process has been allowed to win by default. Latent state and recompute routes still exist, but they get outvoted, even when they are more appropriate for the current token. The gated-attention paper notes that these sink tokens correspond to “massive activations” - huge numerical spikes that propagate through the network and drown out subtler signals. In this context, the gate functions exactly like a “noise gate” in audio engineering. It detects that constant, high-volume hum from the anchor heads and clamps it down to zero, the way an audio noise gate kills background hiss when no one is speaking. This lets the actual signal (the recompute and latent threads) come through clearly.
The gated‑attention paper shows that you can almost completely remove this attention-sink pattern by forcing anchor‑style heads to pass through the same gate as everyone else. Once every head has to earn its right to speak based on the current token’s state, the first token stops being a magical attractor. It still matters (prompts still work) but it no longer auto‑wins.
That’s exactly what you’d expect if you believe that attention-sinks are a symptom of a bad arbitration regime, not an inevitable property of transformers.
And it suggests a more general design principle.
Gating as explicit arbitration between processes
Now lets make the mapping explicit.
Some heads behave like latent readers - their patterns say “read from the compact state”. Others behave like route builders - they reach across the prompt to pick up support for local reasoning. A third group behave like anchor heads - they keep you close to instructions, style, or sinks.
A per‑head, query‑dependent gate is, implicitly, a policy over these behavioural families.
On familiar, well‑covered distributions, you’d expect the gate to give more bandwidth to latent readers, reuse amortised structure, and let anchor heads provide gentle steering while heavy recompute stays in reserve. On weird, underspecified, or adversarial inputs, you’d want the opposite - stale latents should be treated with suspicion, recompute heads should get more room to work, and anchors that point the wrong way should have to argue much harder to move the state.
The gated-attention paper never phrases it like this. It talks about efficiency, non‑linearity, and stability. But in practice, that small gate has given the model a new kind of control.
Given what I know right now, which heads (and therefore which internal processes) should actually move me on this step?
That is exactly the question an arbitration mechanism has to answer.
Why this is still emergent (and where fragility hides)
It’s tempting to hear “gating” and imagine a clean, hand‑designed controller reading off neat signals like familiarity or stakes.
But that’s not what’s happening.
All the gate does is provide a small, trainable interface. Designers choose where to put it - after attention heads. They choose what it sees - the current token’s state. They choose its basic shape - a sigmoid, per‑head, with a bias toward sparsity.
Everything else is learned.
Which heads get chronically high or low gates. How gate patterns depend on task or style. When the model decides to trust anchors versus latents versus routes. Those are emergent properties of training data, loss, and the pre‑existing head biases.
This is where fragility comes back in.
If the gate learns a systematically bad arbitration policy for some regime (for example, always trusting anchors when talking about finance, or always suppressing recompute when the user sounds uncertain) you get brittle, predictable failure modes. The architecture didn’t hard‑code those pathologies. It created a place for them to show up.
So the right takeaway isn’t that gating fixes arbitration. It’s subtler. Gating gives us a handle on arbitration. It makes some aspects of the internal argument more explicit and more measurable. It also gives models new ways to go wrong if we don’t look closely.
Which brings us to the practical part.
Why does this matter for how we build and read models?
If you design models, one way to look at this gated-attention paper is very simple - small, context‑dependent gates at the right points don’t just help optimisation, they shape who gets to act inside the model.
But in practice that means we can start to choose where arbitration lives (after attention, around MLPs, at tool boundaries, inside scratchpads) rather than letting it emerge only from the geometry of the residual stream. We can choose what signals it sees - not just the current token’s state, but perhaps explicit measures of conflict, surprise, or safety stance. And we can evaluate architectures not only by perplexity, but by how sane their arbitration policies look across regimes.
If you care about interpretability, the gate is also an invitation. Watching which heads get gated in or out across a sequence is a direct way to see when the model is relying on latents, on routes or on anchors.
The gated-attention paper shows that different heads get vastly different gating scores. This isn’t a global volume knob - it’s a mixing desk.
Combine this with geometric measures of how hard the state is being bent and you can start to separate two questions that usually blur together - who is speaking, and how hard are they pushing?
And if you’re just trying to make sense of LLM behaviour day‑to‑day, the big picture is straightforward.
Models aren’t just “doing attention” in a flat way. They’re constantly arbitrating between memory, reasoning, and prompts.
Tiny architectural choices (like a small, head‑specific gate) can shift that arbitration regime enough to make them feel more or less brittle.
NeurIPS gave a ‘Best Paper’ award to a clever way of stabilising and sparse-ifying attention. Seen from the outside, it makes models faster and a bit more robust. Seen from the inside, it’s another step toward something more interesting - actually reading their heads, and giving them a say in who gets to move the mind they implement.