
What is a 'Latent Model'?
LLMs can create convincing plans or personas - until they suddenly fall apart. The difference isn't magic, just how "internal handles" interact. When they align in the right way it's a "latent model".

There’s a moment that keeps happening when you work with large models. You ask for a plan, or a persona, or a careful explanation and for a while it holds - same stance, same voice and a good sense of where we’re going. Then a throwaway clause or a changed example and the whole thing wobbles and falls apart. If the LLM “knows” about the world, why would a tiny push change its behaviour so dramatically? Or alternatively, if it’s all just parrotry then why do some behaviours persist like muscle memory? Either way we need a good way to explain this.

A good name helps us see what’s really there. Latent is that word for me - not as a hand‑wave, but as a specific kind of internal handle (see my “Latent Confusion” post for a more detailed definition). And when those handles organise themselves in the right way the create something you can rely on. I call that bundle a latent model.
A scene to hold in your head
Imagine you and I are reading the same paragraph with different hats on. You’re the critic and I’m the author. We both track who’s “I” and who’s “you”, we keep a little plan in our mind that maps out where the argument is going, and we can glance back at the opening lines that set it all up if we lose the thread. Three quiet things are happening here: a small state that carries roles, a route that recomputes local inferences as new sentences appear, and an anchor (the first lines) that we can revisit like we had a finger on the first page. When things are running smoothly then these three cooperate. If one of them slips then things can get bumpy.
That three‑way dance is the backdrop for this latent model concept.
The word “latent” reclaimed
In ordinary English, latent means present but not yet expressed. In statistics, a latent variable is an unobserved cause we posit to explain patterns in data. In mechanistic work on neural models, a latent state is more concrete: a direction or small subspace in a layer’s activation where a useful variable is written so later parts of the network can read it.
All three senses matter. The ordinary meaning keeps us honest (there’s something there, but it needs the right conditions). The statistical meaning reminds us what role such a thing should play (explain structure). And the mechanistic meaning gives us the handle (you can adjust it and the behaviour changes).
From pieces to a pattern
I’ve found it useful to talk about three recurring pieces inside model behaviour:
States: compact codes written mid‑stack - like a deictic frame (who’s speaking to whom) or a plan step - that later components reuse. When these are strong, the model feels consistent because it’s reading from it’s own notes.
Routes: input‑conditioned procedures that re‑derive what they need on the fly - gather evidence, compose, use then discard. They’re flexible and powerful, but sensitive to order and wording.
Anchors: early, high‑leverage tokens (system instructions, first examples, etc.) that are easy to look up. They shape the rest of the computation without being recomputed.
You may have seen this trio in other guises in my posts. Here I want to bind them together and give them a name when they behave like a single thing.
The bundle
A latent model is a portable internal scaffold (a small set of states, the motifs/circuits that write and read them, and the routes that recompute when they must) held together by a quiet arbitration policy that decides which of those processes leads on a given step. It’s latent because most of the time you don’t see it directly. You infer it from how behaviour stays the same when the surface changes, and how it bends when you push on particular parts of the computation.
When the bundle is healthy, you feel it as steadiness: the voice stays in character - the plan survives a paragraph break - an entity remains the subject even when pronouns shuffle. When it’s unhealthy, the route keeps winning and the system may seem brilliant and brittle in alternating waves.
Circuits, motifs and what writes the state
“Motif” is the word for a small computational pattern that recurs across prompts: an induction move, a binder that links a name to a description, a little negation suppressor. When you pin one down in a particular network with causal tests, we usually call it a circuit. Circuits are the machinery - states are the artefacts they leave in the residual stream - compact codes that later components can read cheaply. Routes are the sequences where motifs fire in a particular order for this input.
Why am I repeating this point? Because it tells us what kind of thing to look for when behaviour is stable. In many skills the stability doesn’t come from constantly re‑deriving everything - it comes from writing a small state and reading it repeatedly. In other skills, the stability comes from reusing a route whose structure is surprisingly robust. And sometimes the stability is just anchor gravity: the opening lines keep winning the tie‑breakers.
The role of arbitration
The network doesn’t declare which regime it’s in. It chooses, token by token, which process to lean on. Heavy, repeated cues push the system to write a state and amortise the cost. Sparse or contradictory evidence triggers re-computation along a route. Strong early instructions or exemplars act as anchors that everything else orbits. Most prompts mix the three - the interesting question is which leads when. That “which leads” is what I mean by arbitration.
This is also where most of the apparent mystique comes from. Small phrasing changes don’t “confuse” a model in a human way - they flip the arbitration. Change the order of two premises and you moved the entrance to a route. Duplicate the system role and you deepened an anchor. Add a crisp role phrase and you helped the network justify writing a state.
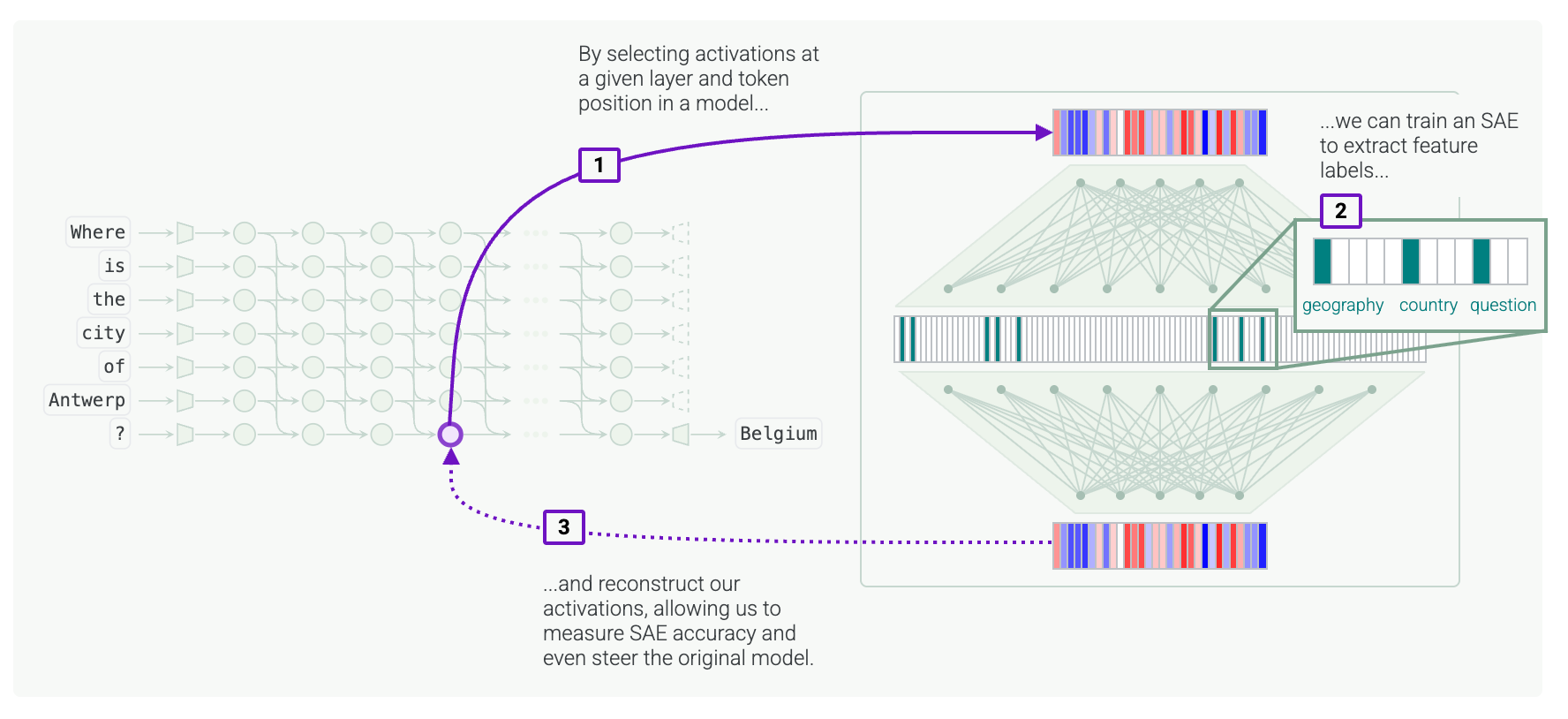
A note on sparse autoencoders (SAEs)
SAEs give us a useful lens here. They learn a dictionary so that a model’s activation can be re‑expressed as a sparse code. Papers call that code “the latent,” and the coordinates “latent neurons.” In this post, when I say latent state I still mean the model’s own activation - the thing later layers read. SAEs are a tool to factor that state into candidate features we can name. If those features really are part of a latent model, updating them and then mapping back into the model’s space should shift behaviour in the same way across phrasing changes. When it doesn’t, we’ve probably found a route‑only trick or a feature that overlaps with too many others to travel well.
Self, other, world
The phrase world model is doing a lot of work in the AI field. Often it is implied, hinted at or just assumed. For example, the recent “Code World Model” paper from Meta literally has the term “World Model” in its project name and mentions it 47 times, yet it doesn’t provide an explicit or formal definition of what they mean by “world model” at all. Here I’m not trying to criticise this paper/project, just to highlight how easily people throw around this term without providing a clear foundation.
I find it is useful to define a “world model” as a stack of latent models at different scales. At the micro scale: deixis, entities, local relations. At the meso scale: plans, roles, norms. At the macro scale: frames, priors, dynamics you can roll forward. Across all three you can add a lens that matters for language: self (who am I in this exchange?), other (what do they likely believe and want?), and world (what are the stable facts and rules?).
In practice, self‑other‑world isn’t three extra modules - it’s a way of talking about which latent models the system recruits and how they vote. A self‑heavy exchange keeps a strong persona state and defers to anchors about tone. An other‑heavy exchange lights up routes that attribute beliefs and write small states about who knows what. A world‑heavy exchange relies on shared facts and predictive routes (in video or embodied settings, these are literal rollouts over time). What matters for us as builders is not to argue which one is “the” model, but to recognise which bundle the network is actually using at any point.
A more careful meaning of “model”
Why call this a model at all? Because it earns the word. A latent model, in this sense, does four things models are supposed to do:
Represent: it carries variables worth naming (deictic roles, plan steps, goals, norms, physical affordances) and keeps them accessible.
Explain: those variables account for regularities in behaviour - when they are strong, behaviour is stable - when they are weak, behaviour flickers.
Predict: when the system chooses a route, it does so to extend those variables through time or across the paragraph - local dynamics in a conversation as much as literal physics in a video.
Respond to interventions: when you update a variable inside the bundle, the behaviour bends in a way that you can anticipate.
That last one is where the concept stops being rhetoric. If you can’t touch it and watch behaviour bend, it’s probably just a story. If you can touch it and the bend is consistent when the surface changes, you’ve located a portable handle.
Why this helps day to day
A lot of everyday confusion evaporates when you adot this view. The “why did the model change its mind?” moments often reduce to “route won over state”, or “anchor won over route”, or “state was underwritten and got overruled by a new clause”. The “why did that fine‑tune help so much?” moments often reduce to “we made reuse frequent enough that the network started writing the state instead of recomputing”. The “why did this persona finally stick?” moments reduce to “we gave the anchor a clear job and let mid‑layers consolidate it into a state”.
It also gives us language for productive disagreement. If you think a model has no internal modelling, you’re really claiming it never writes useful states and can’t reuse them. If you think the model is a magical wizard, you’re forgetting how often those states fail to appear and how much the system relies on anchors and opportunistic routes. The interesting work is in the middle: learning when to encourage writing, when to improve routes, and when to move or duplicate an anchor so the right bundle shows up.
Where this goes next
The reason I care about latent models is not because the phrase is tidy, but because it points to a practice. Build handles you can name. Notice which ones travel. Notice which ones only work when you also encourage a pathway. Pay attention to which leads when the story gets long. Over time, the most useful behaviours look less like a thousand fragile routes and more like a handful of states that the network trusts itself to keep.
That’s the thing I think we’re watching grow: still happy to improvise, still sensitive to the opening notes, but increasingly willing to write things down and read them back. When those pieces click into place, the behaviour stops feeling like a set of tricks and starts feeling like a model - latent at first, then, with the right pressure, something that acts a lot like understanding.
Couldn't agree more. Do you anticipate this 'latent model' framework might offer new avenues for steering model behavior more predictably? This analysis is truely insightful.
Thanks Rainbow Roxy. Absolutely - it gives us tangible handles and levers for exactly that.