
Live Tracking Is About To Change - Again!
Computer Vision based Augmented Reality made Live Tracking Mainstream. Recently this evolved to benefit from AI. And it's now about to go through another revolution.


If you’ve spent any time with the early versions of spatial computing then there’s a particular kind of AR experience you probably got used to. You looked at an object and the system tried to meet you halfway - an asset loaded, then a label, then the label jittered as little as you moved. The overlay was technically “tracking”, but it didn’t feel like the world had been understood. It just felt like a clever sticker fighting to stay attached.
For years that separation was the giveaway. You could tolerate it in a demo, you could forgive it in a prototype, you could even learn to ignore it in a product - but you always felt it. The digital layer was sitting on reality rather than in it.

And then, every so often, you got a glimpse of the opposite as things slowly improved.
You could pan a phone through a room and the overlay didn’t slide. You could lean closer and it didn’t wobble. You’d walk behind a chair and whatever was “there” stayed there, calmly and correctly, as if it belonged. It’s not that the graphics are prettier or the models are bigger. It’s that the experience stopped arguing with your senses.
That’s the threshold that’s been changing over the last year or so - the moment when spatial computing stopped looking like computer vision dressed up as product, and started feeling like a seamless blend of the world around you with worlds that never existed - but behave as if they do. But this evolution is about to accelerate, significantly.
We’ve already lived through one revolution to get here. The quiet one.
We went from hand‑crafted pipelines (the brittle era of tuned thresholds, feature descriptors, geometry tricks, heuristic association rules) to systems that learn to perceive. We replaced cleverness with gradient descent. The results were not subtle. Categories that used to require careful engineering became commodities - pose estimation running in real time on edge devices. Multi‑object tracking (MOT) that holds together under occlusion. Lightweight models that can run in a browser and still give you a surprisingly stable skeleton. Entire libraries became like a muscle memory.
It’s easy to forget how dramatic that shift was because it happened in slow motion and then, suddenly, it was everywhere.

Look at human pose as an example.
You can pick almost any modern baseline and get decent keypoints at a reasonable frame rate - a single‑stage model like YOLO(26) Pose will happily give you COCO joints in one forward pass. ViTPose treats joints as a global relationship problem rather than a local heatmap. And Google MediaPipe / BlazePose keeps the whole thing light enough for phones and browsers while still covering an unusually rich skeleton. If you want the classic “don’t lose resolution” approach you reach for HRNet. If you care about temporal coherence you start looking at designs like HSTPN and multi‑frame approaches like DCPose. And if you’re doing anything even slightly off the main highway you end up in toolboxes like DeepLabCut, because it’s often the quickest way to adapt the machinery to the reality you actually have.
None of this is magic anymore. It’s more like a menu.
Multi‑object tracking (MOT) followed the same arc. First came the tracking‑by‑detection lineage - the pragmatic, industrial path where you detect each frame and then you stitch together identities with association logic.
That family evolved fast - SORT to DeepSORT, and then into the modern wave that made “use the detector, then track everything” feel almost obvious. ByteTrack is the name most people remember because it catalysed that pattern.
At the same time, a second paradigm grew in parallel - end‑to‑end transformers that try to treat tracking as a sequence modelling problem, where the system predicts identities the way language models predict tokens.
If you look at the current crest you can see where the field is trying to go - MOTIP reframing MOT as ID prediction, SambaMOTR modelling synchronised sets of sequences, CO‑MOT playing with coopetition and shadow sets to keep identities stable. And you can see the “make it general” thread running through work like MASA (matching anything by segmenting anything) and GeneralTrack, alongside pragmatic hybrids like Hybrid‑SORT.
Underneath all of it, the detector backbones are shifting too.
CNN workhorses still matter, but more and more stacks are built on transformer detectors such as RF‑DETR and real‑time variants like RT‑DETR, while the YOLO line keeps advancing (people now pair trackers with YOLO as casually as they used to with much older generations).
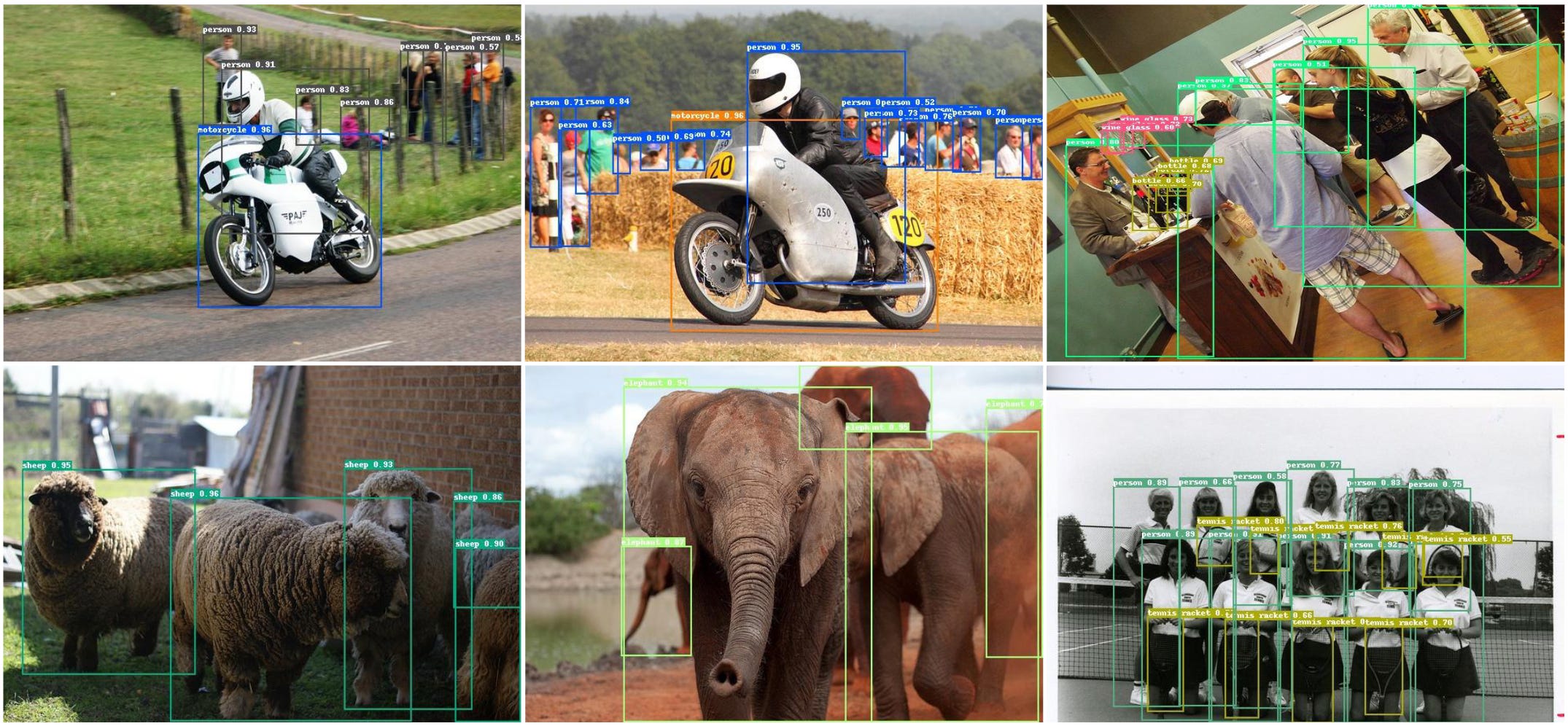
If you read the field’s recent surveys you can feel the split - heuristic‑heavy methods still look surprisingly good when the world behaves. Dense crowds moving in roughly linear motion, predictable trajectories, the kinds of scenes where a good detector plus a sensible association policy can be brutally effective. Meanwhile deep association methods, both tracking‑by‑detection and end‑to‑end, start to dominate when motion becomes messy, the camera gets ambitious, the scene becomes non‑linear, the world stops being polite.
That story (the arms race between heuristics and learning) has been the dominant narrative for the last few years.
But I think we’re at a different kind of inflection point now.
The next revolution is not primarily about trackers becoming “better” in the old sense. It’s about something upstream changing so profoundly that “better tracking” becomes the default outcome of a whole new stack.
The stack itself is starting to invert.
Instead of building a pipeline that extracts the world from raw pixels, we are building systems that can generate worlds - and then train perception inside them, at scale, under controlled variation, with edge cases on demand. At the same time, we are standardising a practical representation of the world that is cheap enough to store, stream, update, and localise against.
World models and 3D Gaussian splatting are the two pillars of that inversion.
On the surface they look like separate threads. One is about synthetic environments and interactive generation. The other is about an uncanny rendering technique that suddenly made photorealistic scenes run in real time.
But if you follow the direction of travel, they converge into something else - a data plane for reality.
The collapse
The first clue that something structural is changing is how quickly specialised vision pipelines are being eaten by general models.
A few years ago, segmentation was a task. You had a model for it, you trained it, you tuned it, you deployed it. You treated masks as outputs in a pipeline.
Then the Segment Anything family showed up and segmentation became interaction. The model didn’t just output a mask, it responded to prompts. A point, a box, a scribble. The mask was not a prediction, it was a negotiation.
When SAM moved into video as SAM 2, the negotiation gained memory. It started to carry context through time, to handle motion and occlusion, to act like a system that could keep an object in mind.
As the ecosystem expanded - SAM 2 pushing tracking “at any granularity” via prompts and a unified decoder, and the more speculative leap towards SAM 3 with open‑vocabulary text prompting (with SAM3D reaching toward single‑image 3D reconstruction) - the interesting work shifted from “how do we segment?” to “how do we manage memory?”

Different variants started to look like governance policies. SAMURAI reads like motion‑aware memory selection made explicit. DAM4SAM is a set of rules for dealing with distractors before they poison the memory. SAM2Long reaches for multiple parallel memory banks so long sequences don’t decay into mush. MoSAM pulls motion into the prompting loop so the model doesn’t have to infer dynamics from scratch.
It’s tempting to treat these as incremental research tweaks. But together they’re a sign that we’re moving from models that predict to systems that manage coherence.
And once coherence management is the game, you can start chaining models together.
The emerging “pipeline 2.0” looks less like classical CV and more like orchestration - a model that can produce a rough localisation. A foundation segmenter that turns that into precise masks. A tracker that keeps those masks stable. A prompt policy that decides what counts as “the same thing” across time.
You can already see this becoming a pattern in the wild - ChatGPT, Claude or Gemini proposes a box. SAM 2 turns it into a mask and keeps it alive.
Open‑vocabulary detectors like YOLO‑World do the same job when you’d rather not rely on a VLM to propose the first guess. And you can feel where it’s going when you see work like Seg2Track‑SAM2 claiming zero‑shot MOT+segmentation behaviour.
The point isn’t the leaderboard, it’s the direction - tracking as a callable capability, not a bespoke pipeline.
In that world, the core product question is not “which tracker is best?” It’s “what are the controls?”
Where do you let the model drift? How do you recover? How do you handle occlusion? What does the system do when the user moves quickly, or when lighting changes, or when a hand enters the frame and blocks the object you care about?
The moat becomes the control surface - the interface between a general perception engine and a specific experience.
TrustIndex pressure: as creation friction drops, Fidelity pressure rises. Generated output stops being seen as “content” and starts being seen as part of your lived environment - which makes failures feel less like bugs and more like reality glitching.
Anchors - the world needs places to stick
Seamless spatial computing doesn’t just require recognising objects. It requires anchoring them - knowing where they are, how they’re oriented, and how that relationship changes as you move.
This is where 6DoF object pose and camera localisation matter, and where the trend lines get interesting.
For a long time, robust 6DoF tracking felt like the territory of specialised setups. Depth sensors helped. Markers helped. Carefully curated object models helped. The constraint was always the same - the world is three‑dimensional, the camera gives you a two‑dimensional slice, and you need to reconstruct enough geometry to make interaction believable.
But the field has been moving towards “RGB‑only is winning”. Not as a philosophical preference, but as an inevitability.
If you can do 6DoF pose estimation and tracking on novel objects without fine‑tuning, you’ve removed an entire category of friction. FoundationPose is the cleanest signal there - a foundation‑model approach to 6D pose that aims to work on novel objects without the usual object‑specific retraining rituals.
If you can do it in real time with RGB alone (inferring depth as needed, recovering gracefully when things go wrong) then you’ve changed the economics of spatial interaction. RGBTrack makes the bet explicit - RGB‑only, practical recovery policies, and a path to consumer deployment without assuming LiDAR as a crutch. Around that you can see the broader push toward generalisability - ideas like ConceptPose using VLM‑style priors for open‑vocabulary 3D concept maps. Iterative model‑free methods like iG‑6DoF. Memory‑queue thinking like PoseStreamer. And approaches that explicitly connect pose estimation to splats, like GS‑Pose.
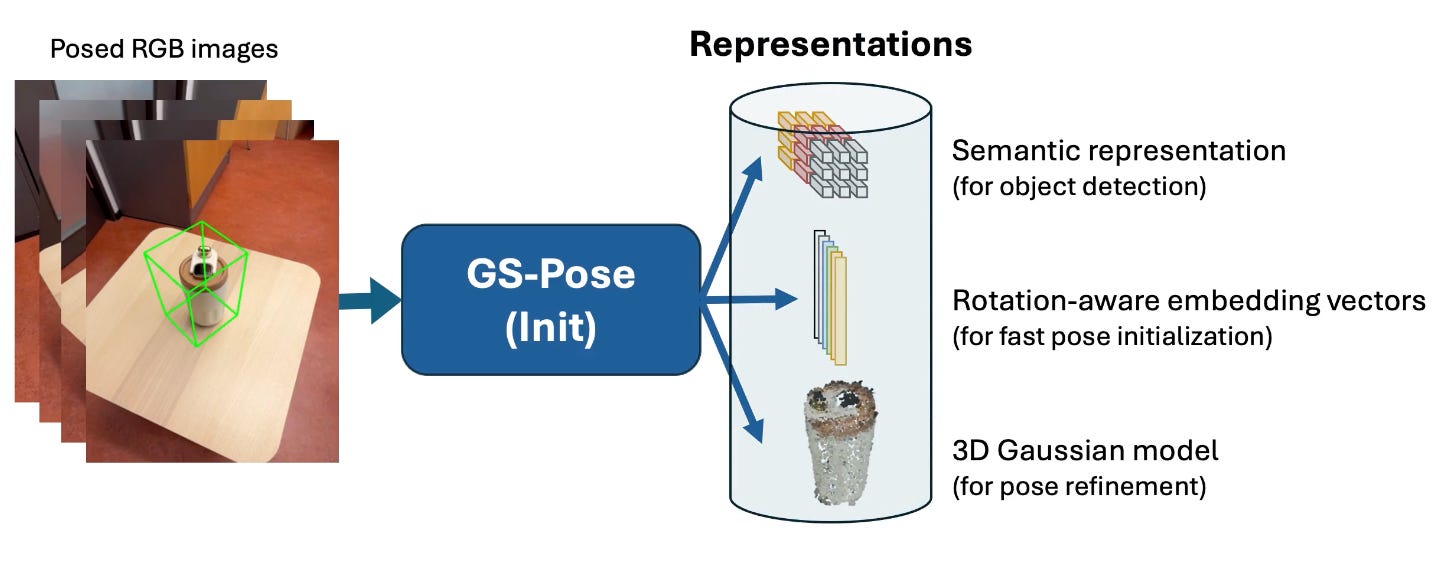
Suddenly any phone camera becomes a viable sensor for experiences that used to require specialised hardware.
Camera pose tracking has its own parallel story. Classical SLAM is a triumph of geometry, but it has always been fragile in the ways that matter for consumer experiences - dynamic scenes, changing lighting, textureless surfaces, environments that don’t sit still.
So we started augmenting it. Deep learning for retrieval and matching. Semantics to avoid treating moving objects as static landmarks.
People are literally wiring detectors and segmenters into systems like ORB‑SLAM3 now, because dynamic environments are where classical geometry has always looked most fragile. Event camera SLAM became a serious thread. Even direct pose regression models (PoseNet, MapNet, DeepVO) that try to bypass the whole geometric stack.
And then 3D Gaussian splatting entered the discussion.
Because once you have a representation that can capture a scene with high visual fidelity and render it efficiently, you can start using it as a map. Not a point cloud, not a mesh, but a dense, photorealistic substrate that the camera can localise against.
The result has been an explosion of work connecting splats to localisation.
GSplatLoc and SplatLoc, newer work like STDLoc and 3DGS‑Loc, semantic variants like SGLoc, and robust relocalisation threads such as GS‑Loc that explicitly lean on vision foundation models to make the representation less brittle.
It’s a sign that 3DGS is not just a rendering technique, it’s becoming a practical spatial medium.
Splats as the ‘JPEG of 3D’
The “JPEG of 3D” metaphor gets used a lot, and it’s useful…but it’s also incomplete.
JPEG didn’t win because it was the prettiest image format. It won because it was good enough, cheap enough, and standardised enough that the rest of the world could build around it.
That’s what’s starting to happen with Gaussian splats.
In a remarkably short period (about 18-24 months by some counts) we went from a research paper showing real‑time rendering to mobile‑friendly capture pipelines, to city‑scale real‑time systems like FlashGS, to practical compression and streaming techniques like Voyager that make splats viable as content you can move around.
More importantly, we’re seeing early standardisation efforts - the glTF ecosystem absorbing splats, and compact containers like SPZ designed to make them interoperable.
This is the boring part of revolutions - file formats and interchange layers. But it’s also where revolutions become inevitable.
Once a representation can move between tools, engines, and devices, it stops being a novelty and becomes infrastructure. And you can see that infrastructure taking shape as systems.
Online mapping and tracking like SplaTAM and GS-SLAM. Dynamic and relightable worlds like 4D‑GS and LiveGS. Practical tooling like gsplat in the Nerfstudio ecosystem. And product‑adjacent work like Niantic Morpheus, which treats splats as something you can edit rather than merely capture.
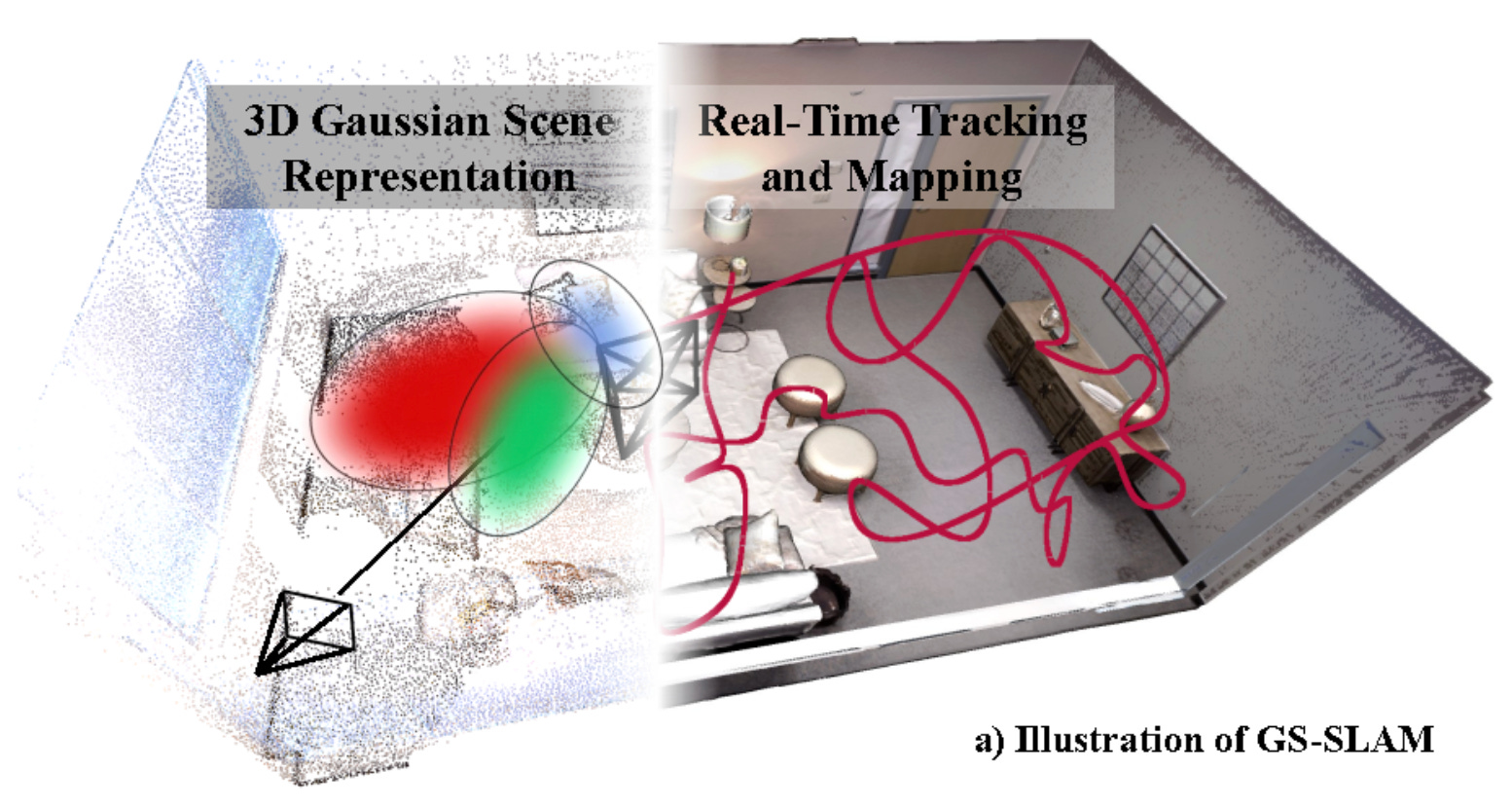
And infrastructure changes the question.
Instead of asking, “Can we reconstruct this environment?” we start asking, “Can we persist it? Can we update it? Can we share it? Can we localise against it reliably?”
That is exactly the set of questions you need to answer if you want spatial computing to become seamless.
Because seamlessness requires persistence. It requires the digital layer to behave like it belongs, not just in a single session but across time. It requires the world to have memory.
TrustIndex pressure: persistence pulls on Portability. Once your world is a living artefact (splats, anchors, edits, shared maps) switching providers stops being ‘export my data’ and becomes ‘move my environment’.
The training factory - when worlds become synthetic by default
Now we reach the real inflection point that’s just starting to hit.
The bottleneck for tracking has never been ideas. The ideas are abundant. The bottleneck has been data - diverse, labelled, messy, in‑the‑wild data that covers the edges rather than the centre.
If you’ve ever tried to harden a spatial system for real users, you know where it breaks. Not in the lab. In the weird lighting. The overly sparse bathroom, or overly cluttered kitchen. The reflective surfaces. The unusual object that looks like three things at once. The moment the user moves faster than your assumptions. The day it rains and everything changes.
The cost of collecting those edge cases is what has kept many spatial experiences narrow.
World models flip that.
They are not simply “better simulators”. They’re a new kind of primitive - systems that can generate environments, trajectories, sensor outputs, and rare events on demand - and then use those synthetic worlds to train perception stacks that will run in the real world.
You can see the pattern forming across the major players.
There are general interactive world models that can generate navigable environments in real time from prompts, maintaining a kind of visual memory and physical consistency for long enough to be useful.
DeepMind’s Genie 3 is the latest and cleanest marker here, and the existence of a consumer‑facing Project Genie preview is an early hint about where this is heading.
There are infrastructure platforms designed explicitly for physical AI - NVIDIA Cosmos, with its Predict / Transfer / Reason framing and its tight coupling to synthetic data tooling.
There are commercial products focused on persistent, downloadable 3D worlds that can be created from multimodal inputs and exported in formats that plug directly into the splat ecosystem.
World Labs’ Marble is notable not just because it exists as a product, but because it exports in splats and meshes, and because tools like Chisel make the “structure vs style” separation feel like a deliberate design philosophy rather than a technical trick.
There are multi‑domain, product‑oriented models that condition on actions (camera pose, robot commands) and ship with SDKs designed to slot into robotics workflows. Runway’s GWM‑1 is unusually explicit about this - worlds, robotics, avatars, all as variants of a single direction.
And then there’s the clearest proof point of the whole thesis - the Waymo World Model. A domain‑specific post‑training of the Genie line, producing multi‑sensor simulations that match Waymo’s camera+lidar outputs. It generates scenarios that were never captured by the fleet, and even converts arbitrary dashcam footage into multimodal Waymo‑style sensor simulations. It’s a statement of intent - the general world model becomes a base layer, and domains become post‑training recipes.

That last move matters because it reveals the architecture.
Real data improves the world model. The world model generates synthetic data. Synthetic data trains a better tracker and a better policy. A better deployed system collects harder real data.
And the loop tightens.
This is not a single model improving. It’s a flywheel. And it’s just starting to spin. Once the flywheel exists, “tracking quality” stops being an isolated technical metric and becomes the downstream consequence of an organisation’s ability to run that loop.
TrustIndex pressure: the flywheel makes Fidelity cheap, but it also quietly increases Reality pressure. When the system can generate the edge cases that shape your perception stack, it starts deciding what kinds of worlds you’re trained to see - and what kinds of worlds you’re blind to.
Convergence - generated worlds flowing into real ones
If you connect these threads (promptable perception, RGB‑first anchoring, splats as a spatial substrate, world models as data factories) you end up heading toward a specific destination.
A world where the boundary between capture and generation becomes porous.
First you use the real world to train systems that can track, segment, and localise robustly. Then those systems become good enough that you can seamlessly lay generated content into the real world.
And once you can do that, you can start to do something more ambitious - blend generated worlds into and over the world around you, in a way that feels less like an overlay and more like a new layer of reality.
This is the moment spatial computing becomes really seamless. Not because the graphics are better. Because the experience becomes coherent under your motion. Because the system’s internal world model (whether it is reconstructive, generative, or some hybrid) matches the way your senses expect the world to behave.
TrustIndex: Fidelity takes the cleanest hit
If we instrument this with the TrustIndex, the cleanest pressure is on Fidelity.
Fidelity is where spatial computing either becomes mundane (quietly useful, like glasses) or becomes perpetually uncanny. It is the dial that captures whether the mediated layer feels believable, whether it integrates with your environment, whether it holds up during interaction.
The new wave we’re describing is essentially a Fidelity engine.
Better tracking increases Fidelity because it stabilises the relationship between you and the world. Better anchoring increases Fidelity because it makes the digital layer behave like it has weight. Splats increase Fidelity because they give us a way to store and render the world with high visual realism at practical cost. World models increase Fidelity because they allow us to train the entire stack under far more diverse conditions than we can collect.
But Fidelity doesn’t rise in isolation.
As the seam disappears, Reality (the degree to which the system mediates perception and action) starts to move as well. When the blended layer becomes the default way you see, the interface becomes a filter on more of your attention and a guide for more of your behaviour.
Transparency becomes harder too. The better the blend, the higher the cost of provenance. This mediation becomes less visible, because the user cannot rely on “it looks fake” as a cue. We’re already well past this with Generative AI Video, and this inflection point will let that leak into the real world.
Portability becomes a new kind of lock‑in. If your experience depends on a vendor’s world layer (their map formats, their memory policies, their identity and anchoring systems) then switching stops being “move my data” and becomes “move my reality interface”.
This is why I think Fidelity is the right dial to watch. Not because it’s the only one that matters. Because it’s the one that changes the moment this technology stops feeling like a demo. And all the other changes here flow from that.
Who gets edit rights?
There’s a comforting story we tell about spatial computing, where the goal is simply to make digital things sit properly in the real world. But the trajectory here points somewhere stranger.
When tracking becomes robust, and when the world can be captured and represented cheaply, and when synthetic environments can be generated at will, the question stops being, “Can we overlay content?”
The question becomes, “What do we let reality become?”
Because a seamless blend is not just a technical achievement. It’s a choice about what counts as real enough to act on.
And once the seam disappears, that choice moves from the user’s conscious awareness into the system’s defaults - what it remembers, what it forgets, what it stabilises, what it edits, what it smooths over.
If the future of spatial computing is a world where generated worlds flow into real ones without friction, then the most important question may not be how fast we can track, or how photorealistic we can render.
It may be simpler.
When the world is editable, who gets the edit rights? This is why the TrustIndex’s Equality dial is so important.
Join in as we track this slope and stay up-to-date. You can always find the current dashboard at TrustIndex.today and subscribe for regular updates as new Signals arrive, weekly Briefings are published and new Reports are released.