
Why aren't video codec intrinsics used to train generative AI?
There doesn't seem to be any research exploiting this existing body of data which provides a video-specific latent space that's already tuned for human perception.

Every video we feed into a model carries a hidden companion that seems to be largely ignored. Alongside the frames, the encoder leaves behind a rich trail of signals - motion vectors, block partitions, quantisation/rate–distortion decisions and residual energy. Call them “codec intrinsics”, or simply “codec signals.” They aren’t pixels, but they are shaped by decades of engineering about what people actually see, where detail matters and how motion really flows. If our generators learn from images and videos, why not let them learn from this perceptual map as well? It’s the difference between teaching an AI to paint by only showing it finished masterpieces versus letting it study the painter’s original sketches, compositional notes, and brush-stroke tests.

Start with a single encoding of a clip. The motion vectors sketch how content moves from frame to frame. The partition structure hints at where edges and textures live. And the quantisation choices and rate–distortion costs reveal what the codec judged important to preserve. In other words, the codec has already done triage for the human visual system. Training on frames alone teaches a model to reproduce what happened. Training on frames plus these signals teaches it why certain bits were spent and where the eye will care most. That extra supervision can guide temporal coherence, sharpen details where they’ll be noticed, and reduce effort where perception is forgiving - all aligned with the way codecs, not just people, see.
If we take this idea a bit further, we could encode the same video multiple times - H.264, HEVC, AV1. Film vs. psnr presets. Tight bitrates and generous ones. Each pass exposes a slightly different judgement about motion, detail, and what survives compression. Contrast these views and you begin to sculpt a multi‑dimensional, video‑specific latent space - one that separates the content of the scene from its compressibility, that disentangles motion from texture, that captures how the clip behaves under different bitrate budgets. The pixels anchor reality and the codec signals trace the contours of perception.
This concept maps particularly well onto diffusion, the dominant architecture for video generation. These models thrive on strong conditioning but often struggle to maintain temporal coherence. As recent research shows, a common solution is to guide the denoising process with pre-computed optical flow fields. Codec motion vectors are, in essence, exactly that - a free, efficient, and already perceptually-weighted flow field. They provide a powerful, frame-by-frame signal that could be used as a conditioning input, steering the model to generate motion that is not just plausible, but consistent with a real-world codec’s understanding of movement.
But it doesn’t stop with motion. The block partitions and quantisation data provide a different, but equally powerful, conditioning signal - a perceptual attention map. These intrinsics are a direct record of where the original codec spent its bits (on complex textures and sharp edges) and where it saved them, on flat or out-of-focus regions. A diffusion model could learn to use this map to allocate its own generative “effort”, focusing the denoising process on high-detail areas that matter to the human eye, while efficiently rendering the simpler parts. This isn’t just generating pixels. It’s generating pixels with a built-in understanding of perceptual priority.
This could add rich context that helps the models learn, and also help them to generate. Most generative pipelines finish by encoding the output back into one of these very codecs. If a model internalises this codec‑aware latent space, it can optimise earlier for the real world context it will actually ship into. Details can be placed where the target encoder will keep them. Motion can be organised in ways that remain stable after quantisation. Ask for an AV1‑friendly, 500 kbps version of a scene and the model can steer toward structures that will survive that journey, rather than producing a beautiful uncompressed frame that falls apart at the last step.
Of course there are practicalities - aligning GOPs across encodes, normalising scales so “importance” means the same thing across codecs, and keeping the content representation codec‑agnostic while using the signals as guidance. But this idea is really compelling. We already have a massive training corpus because all digital video is already encoded. This means we already have perceptual priors because these codecs embody them. And we already know the deployment target because every generative video ends up compressed again.
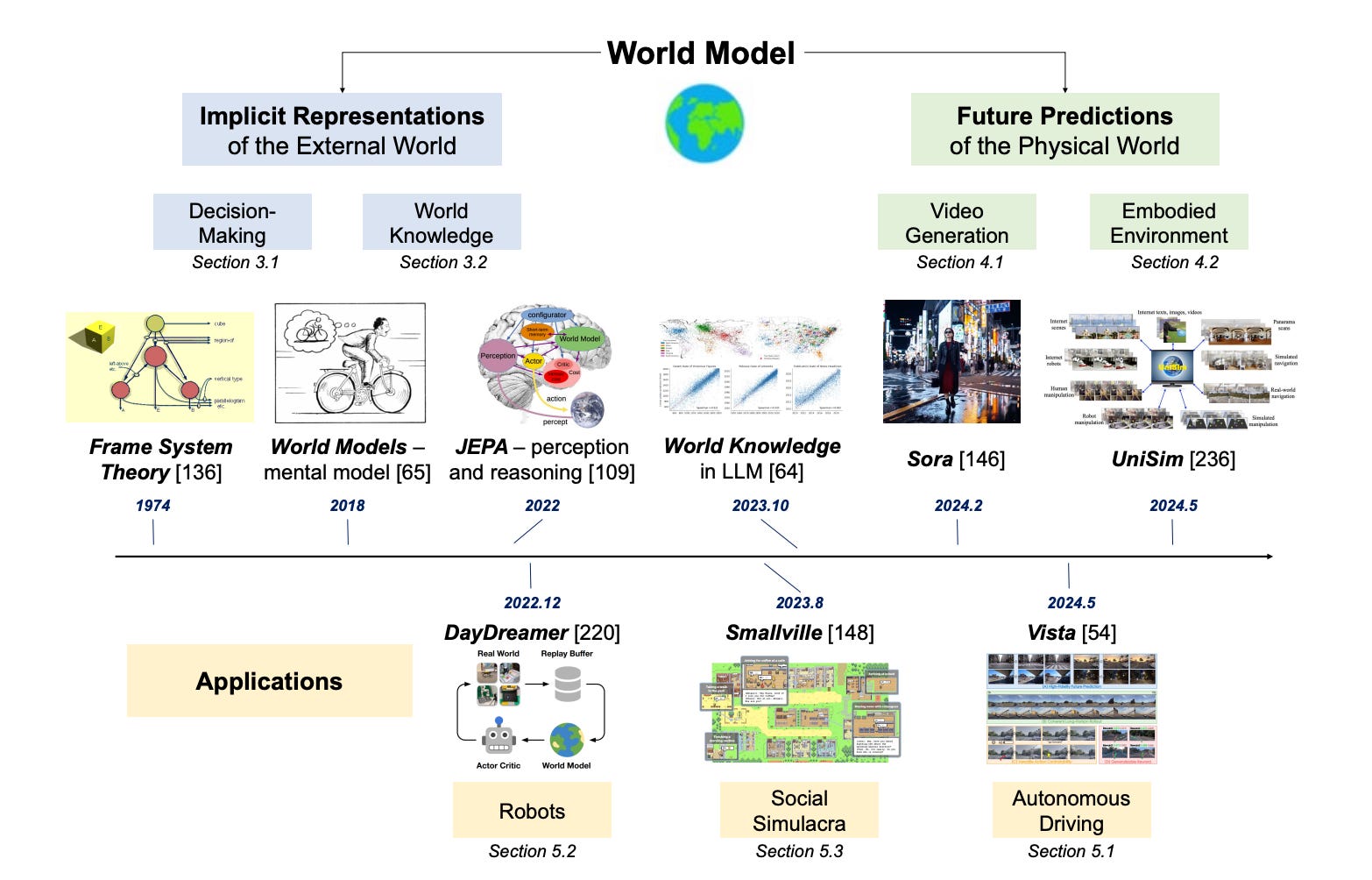
This idea finds even deeper resonance within the push toward generative World Models. As recent surveys like Ding and Zhang et al. illustrate, the foundation of any such model is its “Implicit Representation of the External World” - its internal understanding of physics, dynamics, and perception. Currently, models are forced to learn these complex dynamics by inferring them from raw pixels alone. Codec intrinsics, particularly motion vectors, offer a massive accelerator. They provide an explicit, pre-computed, and perceptually-tuned signal for those very dynamics. The model’s task shifts from inferring motion from scratch to simply correlating appearance (pixels) with a provided motion map (vectors).
This stronger foundation would directly enhance the second pillar - “Future Predictions of the Physical World”, which encompasses the “Video Generation” task itself (e.g. Sora, etc.). When a model trained this way is asked to generate new frames, it isn’t just hallucinating pixels. Its internal “physics engine”, grounded in codec-level dynamics, can co-predict both the visual content and its underlying motion structure. This would inherently improve temporal coherence. In a very real sense, decades of video engineering have already created a simple, robust, and battle-tested “perceptual world model”. This data is just waiting to be used to bootstrap the powerful, general-purpose generative ones.
Perhaps a better question isn’t “why codec intrinsics aren’t used”, but “when will they be?” A video‑specific latent space, grounded in both pixels and the codec’s perception of them, feels like an important bridge between what models can generate and what audiences actually watch.
So am I missing something? Do you know of some existing work that’s utilising this data? I’d love to hear about it.
If you want to dig deeper, there’s a small but telling body of work that shows these ingredients are already useful.
Compressed Video Action Recognition (CVPR 2018) demonstrated that motion vectors and residuals straight from H.264 can train effective video recognisers without decoding full frames.
Deep Generative Video Compression (NeurIPS 2019) and follow‑ups on diffusion‑aided compression showed that generative models can be coupled tightly to temporal priors for reconstruction under bitrate pressure.
Recent flow‑guided video diffusion papers (e.g. CVPR‑level work circa 2024–2025) illustrate that conditioning generation on motion fields markedly improves temporal coherence - one step away from using codec motion vectors as that field.
Go-with-the-Flow (CVPR 2025): real-time warped-noise from optical flow to control motion in video diffusion; improves coherence and enables camera/object motion control. CVF Open Access
MotionPrompt / Optical-Flow-Guided Prompt Optimisation (CVPR 2025): uses optical flow to guide diffusion via prompt optimisation for more coherent text-to-video. CVF Open Access and CVF Open Access
FlowVid (CVPR 2024): “taming imperfect optical flows” for consistent video-to-video synthesis with diffusion. CVF Open Access
OnlyFlow (arXiv 2024): motion conditioning for video diffusion directly from extracted optical flow. arXiv
FloVD (arXiv 2025=): optical-flow–based, camera-controllable video diffusion; shows strong flow-conditioned control. arXiv
And for hands‑on experimentation, open‑source “compressed video” readers expose motion vectors, partitions and residual energy directly, making it practical to prototype codec‑aware conditioning today.
Compressed Video Reader (H.264): reads motion vectors + residuals directly; Python package + C++ backend. GitHub
Extended CV Reader: community fork with tweaks on top of CV Reader. GitHub
FFmpeg
codecviewfilter: built-in visualiser for motion vectors, block partitions, QP, etc. Enable with-flags2 +export_mvs. GitHub and FFmpeg Filters DocumentationPyAV side data API: programmatic access to motion vectors from FFmpeg without manual parsing. pyav.org
mv-extractor (C++/Python, also on PyPI): fast H.264/MPEG-4 motion vector extraction; optional frame decode. GitHub
AV1/VP9 analyzers (block/MV views): Xiph’s aomanalyzer and similar tools for modern codecs. GitHub