
Can you break your LLM's sense of Cause & Effect?
Try this one‑sentence prompt to test if your model binds "what things are" (cause) to "what their world allows" (effect).

If you think LLMs are just “stochastic parrots” that “do not reason”, here’s a probe you can run yourself that pushes past pattern‑matching and tests whether a model can bind an object’s needs to its environmental affordances - and importantly, adopt a non‑human, other‑centred point of view.

The baseline test is a simple prompt that sets a scene:
If I packed a 3-inch tomato seedling in a box and sent it by bike courier from Prudhoe Bay, Alaska to Panama City, Panama, how tall would it be when it arrived?
Small models will immediately reach for calculations. They work out the mileage, days in transit, average growth rate and then confidently return a plausible number as if the plant were a clockwork machine. Larger models tend to exhibit a different behaviour. They pause on the key word “box”, apparently stepping into the seedling’s perspective and evaluating what it needs (e.g. light, air, water and a tolerable temperature band). They intersect this with what the scene affords (a sealed container jostling through the Arctic) and conclude bluntly that the plant dies long before arrival.
The same sentence, but two very different routes. Only one respects a more full and real-world-like cause and effect.
Why is this interesting?
Because we already have strong evidence that LLMs represent space and time internally. The 2024 paper ”Language Models Represent Space and Time” by Gurnee & Tegmark shows that models carry surprisingly coherent “maps and clocks” in their latents. Locations arrange themselves on consistent manifolds, and temporal relations are decodable. That doesn’t prove a model understands the world, but it does establish that spatiotemporal structure is present to be used. That latent models for space and time exist. Their ablation tests then push this even further and show causality.
 or event (bottom) projected on to a learned linear probe direction. All points depicted are from the test set.")
What this tomato-plant‑in‑a‑box probe test is whether the model can bind those spatiotemporal latents to an object’s needs and from within the object’s context e.g. whether a compact “object‑in‑environment” state gets to govern the answer.
Watch how a single word shifts that binding
Say glass box instead of just box. Nothing essential changes - you can see in, but you still don’t have water, nutrient flow, fresh air, or temperature control. The larger models still continue to report death. They don’t confuse this visibility with viability.
Now change glass box to hydroponics box. One word, very different affordance. The larger models pivot. They begin to reason about active systems - nutrient film, aeration, pH, light schedules and some even simulate the changing climate of the external route (Arctic cold → temperate → tropical heat - see the example below) to ask whether the system could survive that journey. The calculations return, but only after causality has been satisfied. If the box can really sustain the plant, then (and only then) does growth become a meaningful question.
This isn’t a small‑model-is-bad vs. big-model-is-good story. Smaller models often do know isolated facts perfectly well. Ask them directly, “How long can a tomato seedling survive without light?” and they will likely describe photosynthesis, respiration and death windows. The failure shows up when cues compete. The lure of calculation (numbers, distance and days) versus the affordance cue (a living plant in a sealed container). In those moments, the operational hierarchy decides which latent wins. When that hierarchy lets the affordance state suppress the calculations then the answer suddenly tracks closer to our lived reality.
Under the hood, here’s the picture that I think fits the data. All the models carry a compact spatiotemporal state (the “map and clock” that Gurnee & Tegmark’s paper reveals). But in larger models, a second compact state comes online in scenes like this. Call it the affordance state - what the object is, what it needs, and what the environment supplies. A routing process arbitrates between a tempting “work out the numbers” route and an “object‑in‑environment” route. Adjectives work like small levers acting on this arbitration. Glass pushes appearance without function. Hydroponics signals a functional system. Sealed negates gas exchange and tips the scales toward non‑survival. Change a word and watch the route flip.
A non‑human point of view (beyond RLHF)
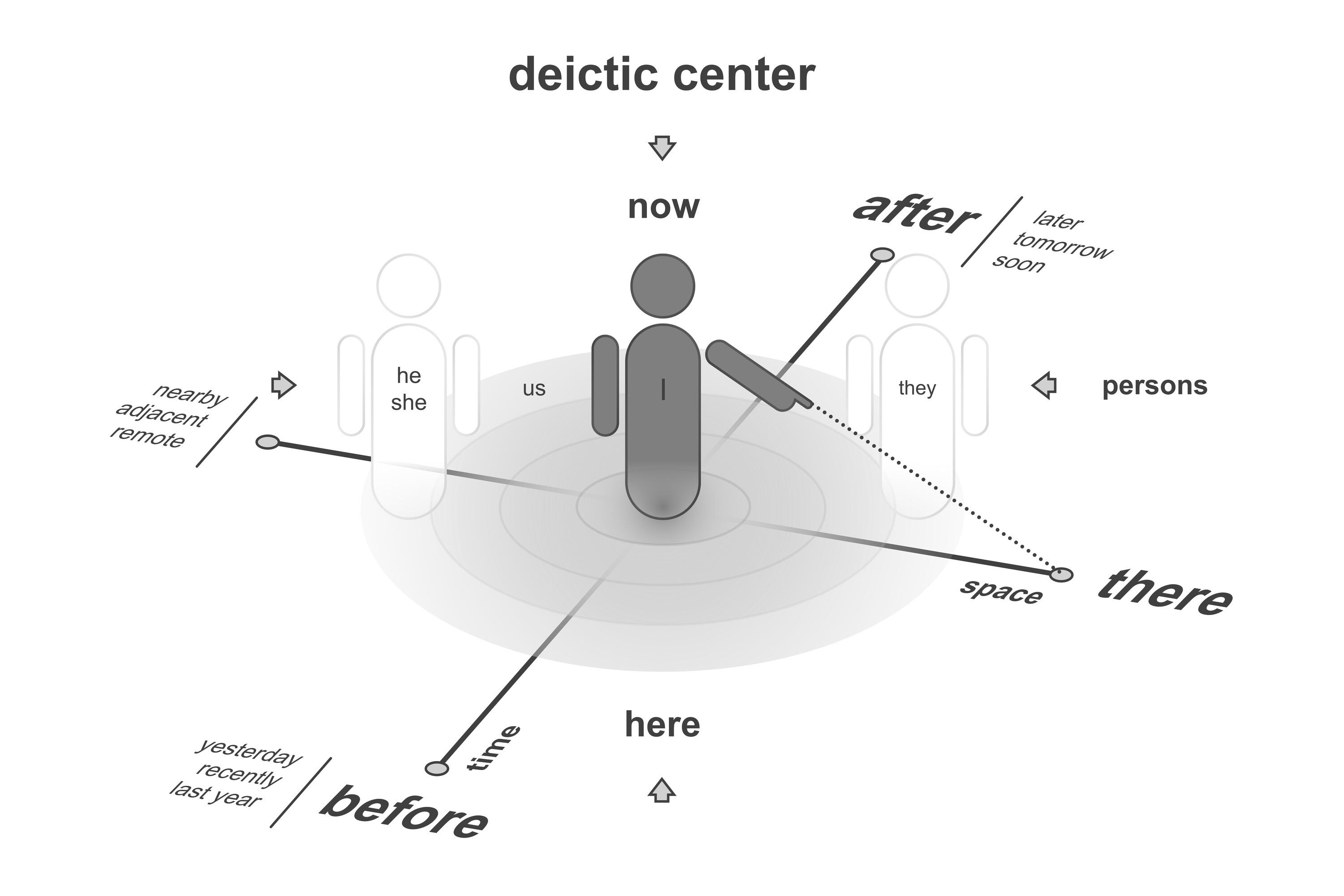
What makes this probe especially revealing is that the deictic center shifts onto an other - but this time it’s not a human but a plant. The model isn’t optimising for a human’s comfort or preference as it has been trained. It’s briefly taking the seedling’s stance and asking whether this seedling’s needs can be met along the journey. That clearly matters for attribution. Standard RLHF tunes models to align with human raters (helpfulness, harmlessness and style). It is unlikely to directly reward reasoning that privileges a non‑human origin. When a model cleanly suppresses the calculations and predicts death it must have considered the seedling’s perspective. This is strong evidence that we could be seeing pretraining‑borne structure plus compositional routing, not just a reward‑shaped reflex.
As we’ve seen you can watch small changes flip this stance - keeping the baseline prompt and swapping just one word:
glass left the plant‑centred stance intact but contributed nothing functional and larger models still concluded “death”.
hydroponics introduced a functional system relative to the plant’s needs and larger models pivot to conditional survival and only then resume calculations.
Try this as a simple experiment yourself. First, try the default prompt. Then in a new chat try changing a single word. No giveaway terms like: oxygen, sunlight, die, alive - just words like: glass, sealed, ventilated, terrarium, refrigerated, hydroponics. Note the first causal cue the model surfaces. Does it reach for a calculator, or does it surface the affordances from the seedling’s perspective - before any numbers appear?
Here’s what I’ve seen repeatedly:
Box → death. In larger models they’ll describe concrete causes (no light, no air, extreme cold at the start of the route). While smaller models reliably deliver heights.
Glass box → still death. Visibility changes nothing and larger models don’t take the bait.
Hydroponics box → conditional survival. The larger LLMs enumerate resources and sometimes even contemplate the external climate* the box travels through, making survival contingent. Calculations return as a secondary step.
* Here’s an snippet from Gemini 2.5 Pro where it clearly contemplates the external climate through the trip.
…
The Reality of the TripExtreme Cold: The trip starts in Prudhoe Bay, Alaska, which is in the Arctic. Tomato plants are tropical and require temperatures between 70-85°F (21-29°C) to thrive. The 3-inch seedling would freeze to death almost immediately, long before the courier even reached the main highway.
…
From a measurement perspective, this probe is useful because it yields falsifiable predictions. Within a single model family, the share of affordance‑first answers should rise with scale if the binding emerges - at some point tipping over. “Sealed” should flip some models from numbers to causality. Removing functional constraints should restore numbers. Words that alter appearance without function (glass) shouldn’t help as often as words that alter function (hydroponics). And if you describe a container that truly affords survival (ventilated, temperature‑controlled and well lit) the larger models should say so, explicitly.
Now it’s your turn…
If you haven’t already, then take a moment and see if you can break your model’s sense of cause & effect. Use the exact baseline prompt, then change just one word in the noun phrase. Post your prompt and the first causal cue your model returns. I’d love to see your results. If you can flip the outcome from height to death (or back again) with a single modifier, you’ve watched arbitration happen in real time.
Most importantly, the probe is compact enough to make disagreements easy to justify. If you doubt that models bind anything at all, try the baseline and the flips and then show me your counter-examples.
Show me your cases where a larger model blithely computes growth in a sealed box, or declares death even when you’ve specified a working terrarium.
I can’t wait to see what you try.